



How many times a day do you talk to a computer? We’re not referring to the exasperated exclamation you direct at your laptop when it overheats and crashes. We want you to think about the moments you speak to a device and it actually listens.
If you call out voice commands to your in-home smart speaker or ask your phone’s voice assistant for the weather forecast, you’re having a conversation with a computer. And you’re not alone. In 2020, there were 4.2 billion digital voice assistants in use around the world, and that number is expected to double by 2024.
Talking to computers — and those computers having the ability to listen to and comprehend what we say — has become the norm. But have you ever stopped to think about how these human–computer interactions are possible?
Today, computers are able to understand natural human language through a technology called automatic speech recognition (ASR). By enabling devices to understand the context and nuance of human language, automatic speech recognition has changed the way we interact with computers forever.
What is automatic speech recognition?
Automatic speech recognition is a technology that converts speech to text in real time. ASR may also be called speech-to-text or, simply, transcription systems. You’re familiar with ASR systems if you’ve ever used virtual assistants such as Apple’s Siri or Amazon’s Alexa. The technology is also implemented in automated subtitling, smart homes, and in-car voice-command systems.
A brief history of speech-recognition technology
Computer scientists have been trying to figure out how to get computers and humans to understand each other since the middle of the 20th century. From the first speech recognizer built in the 1950s to the voice assistants we now speak to daily, speech-recognition technology has certainly evolved from its humble beginnings.
Here’s a quick breakdown of the evolution of ASR:
1952: Bell Labs created an automatic digit-recognition machine named Audrey. Audrey could recognize digits zero to nine when spoken by its creator, HK Davis, with an impressive amount of accuracy—greater than 90%. It performed quite well with other speakers as well, at 70-80% accuracy.
1962: A decade after Audrey was developed, IBM debuted its “Shoebox” machine. The Shoebox understood spoken digits zero through nine, as well as the words “minus, plus, subtotal, total, false, and off.” Toward the end of the 1960s, researchers in the Soviet Union developed an algorithm called dynamic time warping that enabled a recognizer to understand about 200 words.
1971: This year brought about major advances in voice-recognition technology. Interested in a speech recognizer that could understand 1,000 words, the United States Department of Defense funded the Speech Understanding Research (SUR) Program. With funding from that program, computer science researchers at Carnegie Mellon University created Harpy, a speech-recognition machine that understood 1,011 words. An upgrade from the recognizers before it, Harpy could translate complete sentences.
1980s: Cornell professor Fred Jelinek teamed up with IBM to create Tangora, a voice-activated typewriter with a large vocabulary of 20,000 words. Instead of the rule-based approach, where researchers programmed specific parameters into recognizers, the team at IBM used a data-driven, statistical approach to program Tangora to predict speech patterns. It was the first major step toward continuous speech recognition.
1997: Developed and first released by Dragon Systems, Dragon Naturally Speaking was a revolutionary continuous dictation software. Prior to its release, speech recognizers were capable of recognizing only one word at a time. Dragon Naturally Speaking had the capability to recognize 100 words per minute, making it a practical solution for speech-to-text use cases.
2000s: Machine learning has made it possible to train computers to learn the different variations of human language, such as accents, pronunciation, and the context of speech. In 2008, the Google Mobile App (GMA) launched. The app, created for the iPhone, let users conduct voice searches from their mobile devices. GMA allowed Google to collect massive datasets from the search queries conducted on the app. As a result of analyzing this data, Google was able to implement personalized speech recognition on Android phones. Apple followed suit with its iPhone voice assistant, Siri, in 2011, and Microsoft introduced its own voice assistant, Cortana, in 2014.
Speech recognizers have taken quite a few forms since they were first released almost 70 years ago. More advanced technologies opened the door for more wide-ranging capabilities of and uses for speech recognition. But how, exactly, does ASR enable computers to comprehend human speech?
How automatic speech recognition works
In the simplest terms, speech recognition occurs when a computer receives audio input from a person speaking, processes that input by breaking down the various components of speech, and then transcribes that speech to text.
Some ASR systems are speaker-dependent and must be trained to recognize particular words and speech patterns. These are essentially the voice-recognition systems used in your smart devices. You need to say specific words and phrases into your phone before the ASR-powered voice assistant starts working in order for it to learn to identify your voice.
Other ASR systems are speaker-independent. These systems do not require any training. Speak-independent systems have the ability to recognize spoken words regardless of the speaker. Speaker-independent systems are practical solutions for business applications like interactive voice response (IVR).
ASR systems are typically composed of three major components — the lexicon, the acoustic model, and the language model — that decode an audio signal and provide the most appropriate transcription.
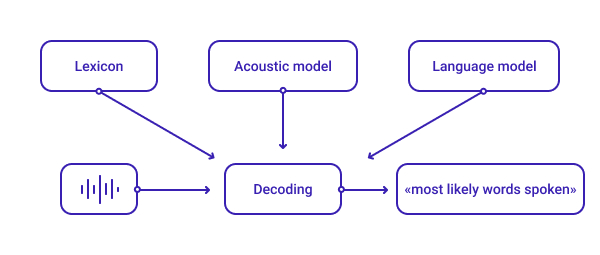
Lexicon
The lexicon is the primary step in decoding speech. Creating a comprehensive lexical design for an ASR system involves including the fundamental elements of both spoken language (the audio input the ASR system receives) and written vocabulary (the text the system sends out).
Lexical design is critical to the performance and accuracy of a speech recognizer because some words can be pronounced in multiple ways. For instance, in English, the word “read” is pronounced differently depending on what tense is used—present or past. A complete lexicon accounts for all of a word’s possible phonetic variants. Comprehensive lexicons are especially important to ensure the accuracy of speech-recognition systems that have large vocabularies.
ASR systems use lexicons customized for each language. One of the most widely used sets is ARPAbet, which represents phonemes and allophones of General American English.
As the foundation used to create customized phonetic sets for different languages, the lexicon is the building block of the acoustic models for every vocal input.
Acoustic Model
Acoustic modeling involves separating an audio signal into small time frames. Acoustic models analyze each frame and provide the probability of using different phonemes in that section of audio. Simply put, acoustic models aim to predict which sound is spoken in each frame.
Acoustic models are important because different people pronounce the same phrase in multiple ways. Factors like background noise and accents can make the same sentence sound different, depending on the speaker.
Acoustic models use deep-learning algorithms trained on hours of various audio recordings and relevant transcripts to determine the relationship between audio frames and phonemes.
A commonly used acoustic model in ASR is the Hidden Markov Model (HMM), which is based on the Markov chain model—a model that predicts the probability of an event based solely on a situation’s current state. HMM makes it possible to include unobservable speech events like part-of-speech tags when determining the probability of which phonemes are used in a particular audio frame.
Language Model
Today’s ASR systems employ natural language processing (NLP) to help computers understand the context of what a speaker says. Language models recognize the intent of spoken phrases and use that knowledge to compose word sequences. They operate in a similar way to acoustic models by using deep neural networks trained on text data to estimate the probability of which word comes next in a phrase.
A common language model that speech-recognition software use to translate spoken word into text formats is N-gram probability, which is used in NLP.
An N-gram is a string of words. For example, “contact center” is a 2-gram, and “omnichannel contact center” is a 3-gram. N-gram probability works by predicting the next word in a sequence, based on known previous words and standard grammar rules.
Together, the lexicon, acoustic model, and language model enable ASR systems to make close-to-accurate predictions about the words and sentences in an audio input.
Figuring out the speech-recognition accuracy of an ASR system requires calculating the word error rate (WER).
The formula for WER is:
WER = substitutions + insertions + deletions / the number of words spoken
While WER is a helpful metric to know, it’s important to note that the utility of speech recognition software shouldn’t be based on this metric alone. Variables such as a speaker’s pronunciation of certain words, a speaker’s recording or microphone quality, and background sounds can affect the WER of a speech-recognition tool. In many cases, even with the mentioned errors present, the decoded audio input may still prove valuable to a user.
ASR use cases
From speech recognition’s mid-twentieth-century origins to its multi-industry applications today, the use cases for ASR technology are far-reaching. ASR made it out of the computer science laboratories and is now integrated into our everyday lives.
Voice assistants
Quite possibly the most ubiquitous ASR use case is the integration of the voice assistants many of us use regularly. According to a 2020 survey conducted by NPR and Edison Research, 63% of respondents said they use a voice assistant.
The ability to use voice commands to help complete tasks like opening up mobile apps, sending a text message, or searching the web affords users a greater level of convenience.
Language learning
For people engaged in self-guided language study, apps using speech-recognition tools put them a step closer to having a comprehensive learning experience during independent study. Apps like Busuu and Babbel use ASR technology to help students practice their pronunciation and accents in their target languages. Using these apps, a student speaks into their phone or computer in their target language. The ASR software listens to that voice input, analyzes it, and if it matches what the system identifies as the correct pronunciation, it informs the learner. If the student’s voice input doesn’t match what the ASR knows to be correct, it will inform the student of their missed pronunciation as well.
Transcription services
One of the first widespread use cases of ASR was for the simple transcription of speech. Speech-to-text services offer a level of convenience in many contexts and also open the door to improved audio and video accessibility.
Health care practitioners use dictation products like Dragon Naturally Speaking to help them take hands-free notes while attending to patients. Podcast transcripts serve as a text-based reference for listeners and offer the opportunity for search engines to crawl and index individual episodes. ASR captioning also allows for real-time transcription of live video, which allows a broader audience to access the media.
Call centers
ASR is crucial for the automation of processes for businesses with extensive customer support demands. With an influx of callers, companies need a way to efficiently handle a vast amount of customer communication. ASR technology is one of the main mechanisms involved in smart IVR — a system that automates routine inbound communications as well as large-scale outbound call campaigns. ASR replaces the dual-tone multi-frequency (DTMF) tones in traditional IVRs so callers can engage with voice bots in their normal speaking voice. Speech-to-text systems enable a smart IVR voice bot to listen to and understand a caller’s request via NLP, helping live agents focus on more complex customer issues.
Learn how companies like Flowwow are using ASR-powered smart IVR voice bots to automate 30% of inbound calls here.
Call centers also utilize ASR to document customer calls, as well as for voice authentication via voice bots. Burger King’s recruitment and assessment department uses Voximplant to program its voice assistant to prescreen job applicants’ calls.
When an applicant calls the recruitment department and answers questions posed by the voice bot, all of their answers are transcribed. When an applicant successfully completes the questionnaire, their call is routed to a live agent, who receives the transcription of the qualified candidate’s phone screen before they’re connected to each other.
How Voximplant leverages ASR
Voximplant provides developers with ASR that captures and transcribes voice input and then returns text to you during or after a call. Voximplant also gives you the power to connect your own speech-to-text provider to our platform via WebSocket.
With Voximplant, you’re equipped with the ASR tools needed to accomplish the following:
- Build smart IVR systems that greet callers and route them to the appropriate agents and departments with voice inputs instead of DTMF.
- Create voice bots to conduct automated research surveys. Your voice bots can ask prerecorded questions and analyze responses in text formats.
- You can create a voice agent using IBM Watson, Google Dialogflow, Microsoft, Amazon, Yandex, and others and connect it to the Voximplant platform.
- Access real-time transcriptions from live conversations between agents and customers to measure call center performance and identify trouble areas.
- Use voice activity detection to filter out background noise for more accurate transcriptions.
Check out this case study to learn how Voximplant uses Google’s Cloud Speech-to-Text API to help companies across industries automate their call center operations with speech recognition tools.
What’s next in ASR?
Modern ASR systems have come a long way since their earliest predecessors. But despite how much they’ve evolved, ASR technology still has further to go before computers can understand and converse with people in the same exact way they talk among themselves. Continued advancements in artificial intelligence have made speech synthesis (also known as text-to-speech) possible for computers, allowing real-time, two-way conversations between a person and an electronic device.
With more innovations inevitably on the horizon, the day when computers converse with us exactly how we converse with each other might not be so far away.
If you’re ready to explore the possibilities of ASR and how it can benefit your business, get in touch with us to schedule a demo!





