



Quantas vezes por dia você fala com um computador? Não estamos nos referindo à exclamação exasperada que você direciona ao seu notebook quando ele superaquece e trava. Queremos que você pense nos momentos que você fala com um dispositivo e ele realmente ouve.
Se você chamar comandos de voz para o alto-falante inteligente de sua casa ou perguntar ao assistente de voz do seu telefone sobre a previsão do tempo, você está conversando com um computador. E você não está sozinho. Em 2020, havia 4,2 bilhões de assistentes de voz digitais em uso em todo o mundo, e esse número deve dobrar até 2024.
Falar com computadores—e aqueles computadores que têm a capacidade de ouvir e compreender o que dizemos—tornou-se a norma. Mas você já parou para pensar em como essas interações entre seres humanos e computador são possíveis?
Hoje, os computadores são capazes de entender a linguagem humana natural através de uma tecnologia chamada reconhecimento automático de fala (ASR). Ao permitir que os dispositivos compreendam o contexto e as nuances da linguagem humana, o reconhecimento automático de fala mudou para sempre a maneira como interagimos com os computadores.
O que é reconhecimento automático de fala?
Reconhecimento automático de fala é uma tecnologia que converte a fala em texto em tempo real. O ASR também pode ser chamado de fala-para-texto ou, simplesmente, sistemas de transcrição. Você está familiarizado com os sistemas ASR se já usou assistentes virtuais, como a Siri da Apple ou a Alexa da Amazon. A tecnologia também é implementada em legendagem automatizada, casas inteligentes e sistemas de comando de voz no carro.
Uma breve história da tecnologia de reconhecimento de fala
Os cientistas da computação têm tentado descobrir como fazer com que computadores e humanos se entendam desde meados do século XX. Desde o primeiro reconhecedor de fala construído na década de 1950 até os assistentes de voz com os quais agora falamos diariamente, a tecnologia de reconhecimento de fala certamente evoluiu desde seu início humilde.
Aqui está uma análise rápida da evolução do ASR:
1952: O Bell Labs criou uma máquina de reconhecimento automático de dígitos chamada Audrey. Audrey conseguia reconhecer dígitos de zero a nove quando falado pelo seu criador, HK Davis, com uma quantidade impressionante de precisão—maior que 90%. Ele teve um desempenho muito bom com outros locutores também, com precisão de 70-80%.
1962: Uma década após o desenvolvimento do Audrey, a IBM estreou sua máquina “Shoebox”. A Shoebox entendia os dígitos falados de zero a nove, bem como as palavras “menos, mais, subtotal, total, falso, e desligado”. No final da década de 1960, os pesquisadores na União Soviética desenvolveram um algoritmo chamado sincronização temporal dinâmica que permitiu a um reconhecedor entender cerca de 200 palavras.
1971: Este ano trouxe grandes avanços na tecnologia de reconhecimento de voz. Interessado em um reconhecedor de fala que pudesse entender 1.000 palavras, o Departamento de Defesa dos Estados Unidos financiou o Programa de Pesquisa de Compreensão da Fala (SUR). Com o financiamento desse programa, pesquisadores de ciência da computação da Universidade Carnegie Mellon criaram a Harpy, uma máquina de reconhecimento de fala que compreendia 1.011 palavras. Como uma atualização dos reconhecedores anteriores, o Harpy poderia traduzir frases completas.
Década de 1980: O professor da Cornell, Fred Jelinek, juntou-se à IBM para criar a Tangora, uma máquina de escrever ativada por voz com um vasto vocabulário de 20.000 palavras. Em vez da abordagem baseada em regras, em que os pesquisadores programaram parâmetros específicos nos reconhecedores, a equipe da IBM usou uma abordagem estatística baseada em dados para programar a Tangora para prever padrões de fala. Foi o primeiro passo importante em direção ao reconhecimento de fala contínuo.
1997: Desenvolvido e lançado pela Dragon Systems, o Dragon Naturally Speaking foi um software de ditado contínuo revolucionário. Antes de seu lançamento, os reconhecedores de fala eram capazes de reconhecer apenas uma palavra por vez. O Dragon Naturally Speaking tinha a capacidade de reconhecer 100 palavras por minuto, tornando-se uma solução prática para casos de uso de fala para texto.
Década de 2000: O aprendizado de máquina tornou possível treinar computadores para aprender as diferentes variações da linguagem humana, como sotaques, pronúncia e o contexto da fala. Em 2008, o aplicativo móvel Google (GMA) foi lançado. O aplicativo criado para o iPhone, permitia que os usuários realizassem buscas por voz em seus dispositivos móveis. O GMA permitiu ao Google coletar enormes conjuntos de dados das consultas de pesquisa realizadas no aplicativo. Como resultado da análise desses dados, o Google foi capaz de implementar reconhecimento de fala personalizado em telefones Android. A Apple seguiu o exemplo com seu assistente de voz do iPhone, Siri, em 2011, e a Microsoft apresentou seu próprio assistente de voz, Cortana, em 2014.
Os reconhecedores assumiram várias formas desde que foram lançados pela primeira vez quase 70 anos atrás. Tecnologias mais avançadas abriram as portas para recursos e usos mais abrangentes de reconhecimento de fala. Mas como, exatamente, o ASR permite que os computadores compreendam a fala humana?
Como o reconhecimento de fala funciona
Em termos mais simples, o reconhecimento de fala ocorre quando um computador recebe entrada de áudio de uma pessoa que está falando, processa essa entrada dividindo os vários componentes da fala e, em seguida, transcreve essa fala em texto.
Alguns sistemas ASR dependem do locutor e devem ser treinados para reconhecer palavras e padrões de fala específicos. Estes são essencialmente os sistemas de reconhecimento de voz usados em seus dispositivos inteligentes. Você precisa dizer palavras e frases específicas em seu telefone antes que o assistente de voz com ASR comece a funcionar para que ele aprenda a identificar sua voz.
Outros sistemas ASR são independentes do locutor. Esses sistemas não requerem nenhum treinamento. Os sistemas independentes de fala têm a capacidade de reconhecer palavras faladas, independentemente de quem está falando. Os sistemas independentes do locutor são soluções práticas para aplicativos empresariais, como unidade de resposta audível (URA).
Os sistemas ASR são normalmente compostos por três componentes principais—o léxico, o modelo acústico e o modelo de idioma—que decodificam um sinal de áudio e fornecem a transcrição mais apropriada.
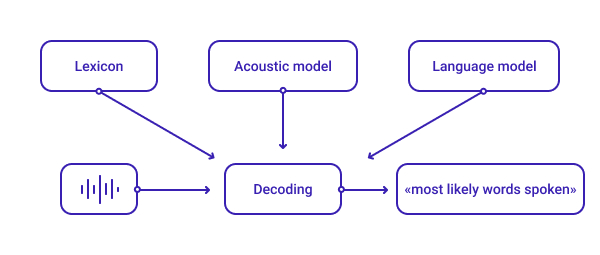
Léxico
O léxico é a etapa principal na decodificação da fala. A criação de um projeto léxico abrangente para um sistema ASR envolve a inclusão dos elementos fundamentais da linguagem falada (a entrada de áudio que o sistema ASR recebe) e do vocabulário escrito (o texto que o sistema envia).
O projeto léxico é fundamental para o desempenho e a precisão de um reconhecedor de fala, porque algumas palavras podem ser pronunciadas de várias maneiras. Por exemplo, em inglês, a palavra "read" é pronunciada de forma diferente dependendo do tempo verbal usado—presente ou passado. Um léxico completo é responsável por todas as variantes fonéticas de uma palavra. Léxicos abrangentes são especialmente importantes para garantir a precisão dos sistemas de reconhecimento de fala que possuem vocabulários extensos.
Os sistemas ASR usam léxicos personalizados para cada idioma. Um dos conjuntos mais utilizados é o ARPAbet, que representa fonemas e alofones do inglês geral americano.
Como a base usada para criar conjuntos fonéticos personalizados para diferentes idiomas, o léxico é o bloco construtivo dos modelos acústicos para cada entrada vocal.
Modelo acústico
A modelagem acústica envolve a separação de um sinal de áudio em pequenos quadros de tempo. Os modelos acústicos analisam cada quadro e fornecem a probabilidade de usar fonemas diferentes nessa seção de áudio. Simplificando, os modelos acústicos visam prever qual som é falado em cada quadro.
Os modelos acústicos são importantes porque diferentes pessoas pronunciam a mesma frase de várias maneiras. Fatores como ruído de fundo e sotaques podem fazer a mesma frase soar diferente, dependendo do locutor.
Os modelos acústicos usam algoritmos de aprendizagem profunda treinados em horas de várias gravações de áudio e transcrições relevantes para determinar a relação entre quadros de áudio e fonemas.
Um modelo acústico comumente usado em ASR é o Modelo Oculto de Markov (HMM), que é baseado no modelo de cadeia de Markov—um modelo que prevê a probabilidade de um evento baseado apenas no estado atual de uma situação. O HMM torna possível incluir eventos de fala não observáveis, como tags de partes da fala, ao determinar a probabilidade de quais fonemas são usados em um determinado quadro de áudio.
Modelo de idioma
Os sistemas ASR atuais empregam o processamento de linguagem natural (PNL) para ajudar os computadores a entender o contexto do que um locutor diz. Os modelos de idioma reconhecem a intenção de frases faladas e usam esse conhecimento para compor seqüências de palavras. Eles operam de maneira semelhante aos modelos acústicos, usando redes neurais profundas treinadas em dados de texto para estimar a probabilidade de qual palavra vem a seguir em uma frase.
Um modelo de idioma comum que o software de reconhecimento de fala usa para traduzir palavras faladas em formatos de texto é a probabilidade de N-gram, que é usada em NLP.
Um N-gram é uma string de palavras. Por exemplo, "contact center" é um 2-gram, e “omnichannel contact center” é um 3-gram. A probabilidade de N-gram funciona prevendo a próxima palavra em uma sequência, com base em palavras anteriores conhecidas e regras gramaticais padrão.
Juntos, o léxico, o modelo acústico e o modelo de idioma permitem que os sistemas ASR façam previsões quase precisas sobre as palavras e frases em uma entrada de áudio.
Descobrir a precisão de reconhecimento de fala de um sistema ASR requer o cálculo da taxa de erro de palavra (WER).
A fórmula para o WER é:
WER = substituições + inserções + deleções / o número de palavras faladas
Embora o WER seja uma métrica útil de se conhecer, é importante observar que a utilidade do software de reconhecimento de fala não deve se basear apenas nessa métrica. Variáveis como a pronúncia de certas palavras por um locutor, a gravação de um locutor ou a qualidade do microfone e sons de fundo podem afetar o WER de uma ferramenta de reconhecimento de fala. Em muitos casos, mesmo com os erros mencionados presentes, a entrada de áudio descodificada ainda pode ser valiosa para um usuário.
Casos de uso do ASR
Desde as origens do reconhecimento de fala em meados do século XX até suas aplicações em vários setores atualmente, os casos de uso da tecnologia ASR são de grande alcance. O ASR saiu dos laboratórios de ciência da computação e agora está integrado à nossa vida cotidiana.
Assistentes de voz
Muito possivelmente o caso de uso de ASR mais onipresente é a integração dos assistentes de voz que muitos de nós usamos regularmente. De acordo com uma pesquisa de 2020 realizada pela NPR e pela Edison Research, 63% dos entrevistados disseram que usam um assistente de voz. A capacidade de usar comandos de voz para ajudar a concluir tarefas como abrir aplicativos móveis, enviar uma mensagem de texto ou pesquisar na web oferece aos usuários um maior nível de conveniência.
Aprendizagem de idiomas
Para pessoas envolvidas no estudo autoguiado de idiomas, os aplicativos que usam ferramentas de reconhecimento de fala dão um passo à frente para ter uma experiência de aprendizagem abrangente durante o estudo independente. Aplicativos como o Busuu e o Babbel usam a tecnologia ASR para ajudar os alunos a praticar a pronúncia e o sotaque em seus idiomas de destino. Usando esses aplicativos, um aluno fala em seu telefone ou computador em seu idioma de destino. O software ASR ouve essa entrada de voz, analisa e, se corresponder ao que o sistema identifica como a pronúncia correta, ele informa ao aluno. Se a entrada de voz do aluno não corresponder ao que o ASR entende estar correto, ele também informará ao aluno sobre sua pronúncia incorreta.
Serviços de transcrição
Um dos primeiros casos de uso generalizado de ASR foi para a simples transcrição de fala. Os serviços de fala-para-texto oferecem um nível de conveniência em muitos contextos e também abrem portas para uma melhor acessibilidade de áudio e vídeo.
Os profissionais de saúde usam produtos de ditado como o Dragon Naturally Speaking para ajudá-los a fazer anotações com as mãos livres enquanto atendem aos pacientes. As transcrições de podcast servem como uma referência baseada em texto para os ouvintes e oferecem a oportunidade para os mecanismos de pesquisa rastrearem e indexarem episódios individuais. A legenda ASR também permite a transcrição em tempo real de vídeo ao vivo, o que permite que um público mais amplo acesse a mídia.
Call centers
O ASR é crucial para a automação de processos para empresas com grandes demandas de suporte ao cliente. Com um afluxo de chamadores, as empresas precisam encontrar uma maneira de lidar de forma eficiente com uma grande quantidade de comunicação com o cliente. A tecnologia ASR é um dos principais mecanismos envolvidos na URA inteligente—um sistema que automatiza as comunicações entrantes de rotina, bem como as campanhas de chamada sainte em larga escala. O ASR substitui os tons de multi-frequência de duplo tom DTMF em URAs tradicionais, para que os chamadores possam interagir com bots de voz com sua voz normal. Os sistemas de fala-para-texto habilitam um bot de voz de URA inteligente a ouvir e entender a solicitação de um chamador via NLP, ajudando os agentes em tempo real a se concentrarem em questões mais complexas do cliente.
Saiba como empresas como a Flowwow estão usando bots de voz com URA inteligente com suporte a ASR para automatizar 30% das chamadas entrantes aqui.
Os call centers também utilizam ASR para documentar chamadas de clientes, bem como para autenticação de voz por meio de bots de voz. O departamento de recrutamento e seleção da Burger King usa a Voximplant para programar seu assistente de voz para pré-selecionar as ligações de candidatos a emprego.
Quando um candidato liga para o departamento de recrutamento e responde a perguntas feitas pelo bot de voz, todas as suas respostas são transcritas. Quando um candidato preenche com sucesso o questionário, sua chamada é encaminhada para um agente em tempo real, que recebe a transcrição da tela do telefone do candidato qualificado antes de se conectarem.
Como a Voximplant potencializa o ASR
A Voximplant fornece aos desenvolvedores um ASR que captura e transcreve a entrada de voz e, em seguida, retorna o texto para você durante ou após uma chamada. A Voximplant também oferece a capacidade de conectar seu próprio provedor de fala-para-texto à nossa plataforma via WebSocket.
Com a Voximplant você está equipado com as ferramentas ASR necessárias para realizar o seguinte:
- Construir sistemas de URA inteligente que cumprimentam os chamadores e encaminham para os agentes e departamentos apropriados com entradas de voz em vez de DTMF.
- Criar bots de voz para conduzir pesquisas automatizadas. Seus bots de voz podem fazer perguntas pré-gravadas e analisar respostas em formatos de texto.
- Criar um agente de voz usando IBM Watson, Google Dialogflow, Microsoft, Amazon, Yandex e outros, e conectá-lo à Plataforma Voximplant.
- Acessar transcrições em tempo real de conversas ao vivo entre agentes e clientes para medir o desempenho do call center e identificar áreas problemáticas.
- Usar a detecção de atividade de voz para filtrar o ruído de fundo e obter transcrições mais precisas.
Confira este estudo de caso para saber como a Voximplant usa a API de fala para texto em nuvem do Google para ajudar empresas de todos os setores a automatizar suas operações de call center com ferramentas de reconhecimento de fala.
O que vem a seguir em ASR?
Os sistemas ASR modernos percorreram um longo caminho desde seus primeiros predecessores. Mas apesar do quanto eles evoluíram, a tecnologia ASR ainda tem que avançar antes que os computadores possam entender e conversar com as pessoas da mesma maneira que elas falam entre si. Avanços contínuos em inteligência artificial tornaram a síntese de fala (também conhecida como texto-para-fala) possível para computadores, permitindo conversas bidirecionais em tempo real entre uma pessoa e um dispositivo eletrônico.
Com mais inovações inevitavelmente no horizonte, o dia em que os computadores conversarem conosco exatamente como conversamos uns com os outros pode não estar tão longe.
Se você está pronto para explorar as possibilidades do ASR e como ele pode beneficiar seu negócio, entre em contato conosco para agendar uma demonstração!





