



Voximplant provides a Text-to-Speech API that allows you to communicate with customers all over the world using their native language.
Text-to-Speech (TTS) technology is the computer-generated simulation of human speech using deep learning methods. It’s commonly used by developers that build voice applications such as IVRs (Interactive Voice Response). This technology is also referred to as speech synthesis.
TTS saves time and money since it eliminates the need to manually record (and re-record) audio files. Instead of playing pre-recorded files, TTS automatically generates a human voice from raw text.
Voximplant provides an API to let customers easily integrate TTS functionality into their app or website. Customers use TTS to handle incoming and outbound calls, as well as manage voice notifications, and no hardware or complicated programming is required.
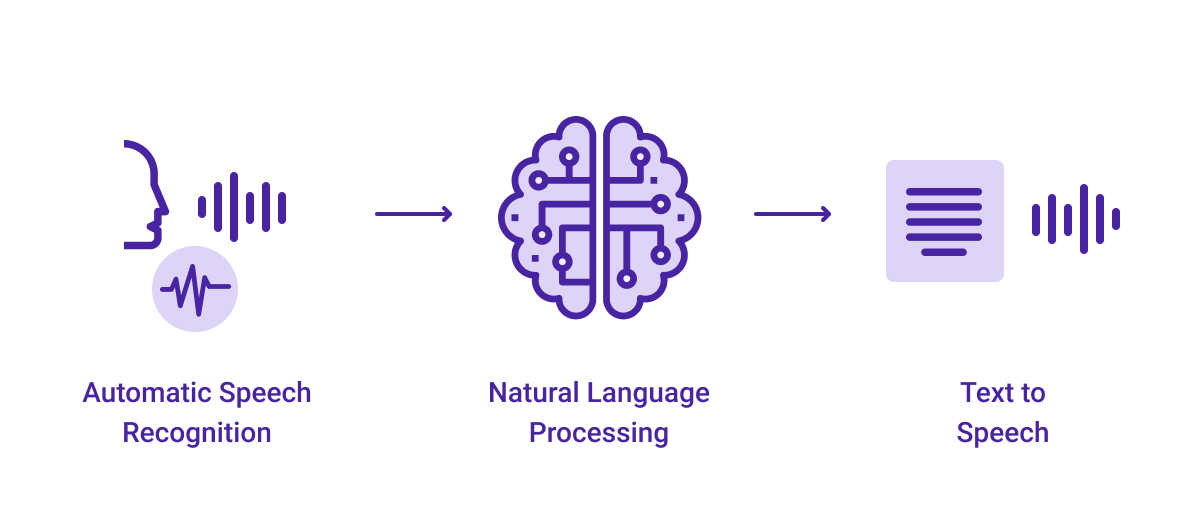
How Does it Work?
Let’s say a voice assistant recognized a text from a customer through your online service. To transform it into a voice, the system has to go through three stages: text to words, words to phonemes, and phonemes to speech.
Text to words
First and foremost, an algorithm has to transform a text into a convenient format. The problem is that raw text is ambiguous. Components like numbers, abbreviations, and dates have to be decoded and broken down into words. Then, the algorithm separates the text into phrases to arrive at the most appropriate intonation. This includes punctuation and stable structures so that a robot can better understand a text and make fewer mistakes while reading.
Words to phonemes
Once the system has figured out the words to spell, a phonetic transcription has to be performed. In other words, the system needs to convert words into phonemes.
Each sentence can be pronounced in different ways depending on the meaning and emotions of the text. Moreover, even a single word can be read in multiple ways. For instance, there are lots of homographs, words that are spelled the same way but pronounced differently.
To understand how to pronounce a word and where to apply an accent, the system uses built-in dictionaries. If the necessary word is missing, the computer builds the transcription on its own, based on academic rules.
Phonemes to speech
Voximplant supports TTS powered by WaveNet to read prepared texts. The same technology is used by Google’s online services such as Google Assistant, Google Search, and Google Translate. WaveNet generates raw audio waveforms using a neural network, which has been trained on a large number of speech samples.
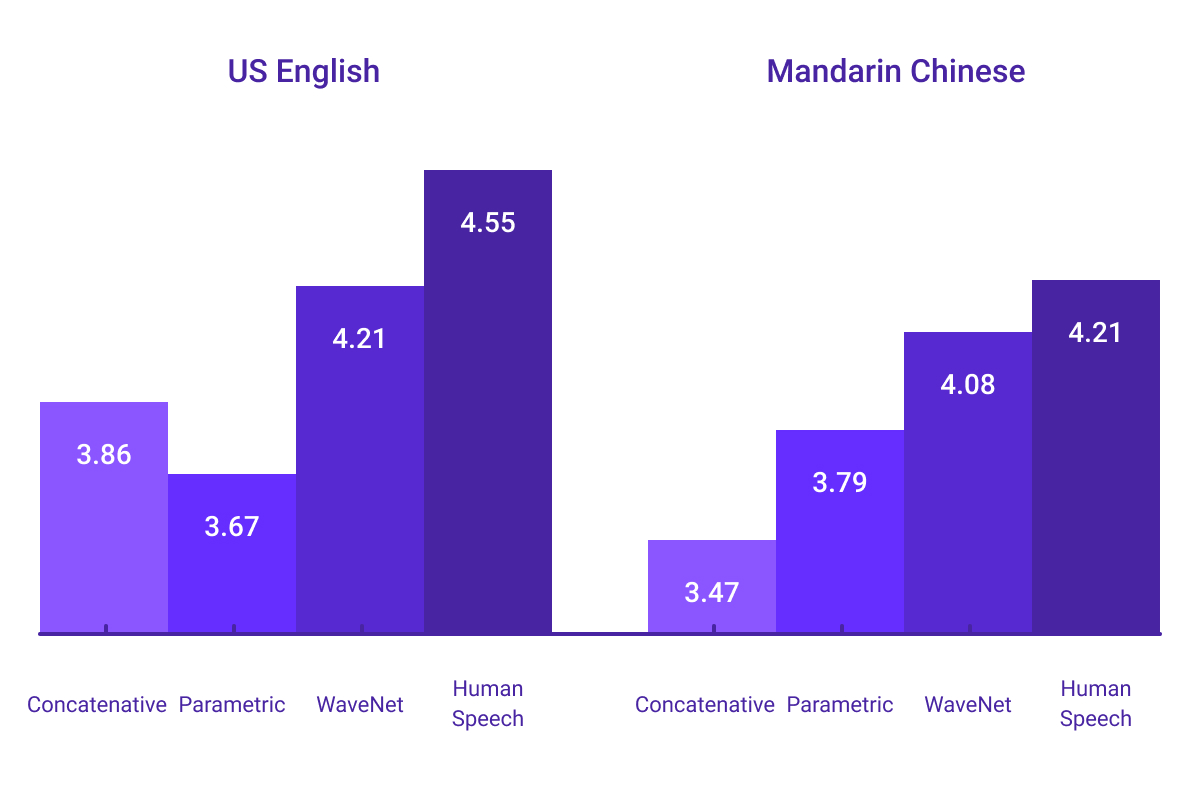
All of the required information for speech generation is stored in the model parameters and the voice tone can be controlled through the model settings. We’ve trained WaveNet using Google’s TTS data sets. The graph below shows WaveNet’s quality compared to Google’s best parametric and concatenative TTS using the Mean Opinion Score (or MOS).
Use Cases
● Smart IVR: Configure your voice assistant to respond to customer requests without the need to involve a live operator.
● Voice alerts: Deliver critical notifications to your customers globally in their native language via phone calls.
● Hotline: Process large numbers of simultaneous clients to broadcast up-to-date information. Find out how KFC implemented a COVID-19 hotline for their employees using Voximplant’s API here.
Features
● Multilingual: Extensive coverage of various languages including US English, Mandarin Chinese, Arabic, and more.
● WaveNet engine: Use WaveNet technology from Google to train the bot according to your business needs.
● Natural voices: Deliver high-quality and natural sounding voices, both male and female.
Free Trial
Sign up for a free Voximplant developer account or talk to our experts. Take advantage of TTS API to automate communications with your international customers. Keep in mind that the premium Text-to-Speech feature is a paid software. Read about our pricing here.
![]()





