



Improving customer experience is an ongoing challenge for contact centers. Striving to offer the best service possible, contact centers are usually very quick to adopt new technologies and try out innovative solutions. Successful implementation of a brand-new customer service technology can create a great competitive advantage for a company, so brands invest a lot of resources in improving customer experiences.
AI-powered speech technologies are, without a doubt, one of the biggest trends right now. They create many interesting opportunities for improving CX. Companies of all sizes are eagerly experimenting with how they can use voice technologies and automation to make customer service better. Market research shows that the majority of modern businesses understand the benefits of AI-powered technologies:
“About 75% of companies plan to invest in automation technologies such as AI and process automation in the next few years. AI, chatbots, voicebots and automated self-service technologies free up call center employees from routine tier-1 support requests and repetitive tasks, so they can focus on more complex issues.” (Source: Deloitte)
How speech technologies help to improve customer experience
Reducing waiting time in queue
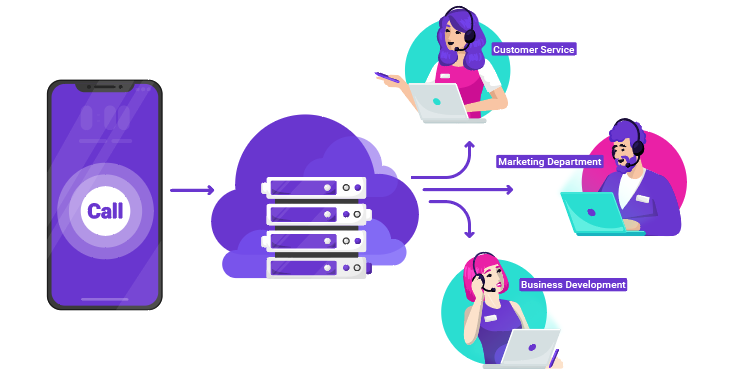
Speech recognition allows for intelligent call routing that ensures all requests are processed in a timely manner and customers don’t have to wait in queues to talk to an agent. A call routing system processes incoming calls and directs them to a specific person or department.
From the customers’ perspective, they are given options to speak with specific departments, request a particular task, among other choices. From the company's perspective, they control attributes of how calls are forwarded, what extensions they reach, and to what magnitude they utilize caller information.
You can set rules that regulate the routing process. With call routing, you can choose the criteria: skills needed for resolving the issue, operator availability, time zones, language preferences, caller identification, etc.
Creating self-service options and reducing agents’ workload
Clients can solve their issue with the help of a voice bot, without talking to a live agent. In many cases, it takes less time and effort to end up with a satisfying result. It is beneficial both for businesses and customers, since clients can find answers to their questions quickly and independently, while your employees won’t be getting overloaded with simple routine tasks. Your agents can focus on more complex issues that require empathy and human approach.
Self-service options also allow you to cut your costs and save budget. On average, a voicevot can process around 80% of calls automatically. It is also three times more affordable than a call center agent, while being more efficient and productive.
Analyzing issues and identifying opportunities for improvement
Contact centers must analyze and understand every customer interaction to identify root causes to issues and offer an improved service over time. Voice technology allows contact centers to transform audio to text which can be analyzed at scale using natural language processing tools. Managers can then extract topics, themes and words from all customer interactions to inform best practices which can be indexed to deliver excellent support.
Research from Atlassian shows that customer satisfaction drops by 15% each time a customer has to call back to resolve their issue. Speech technologies allow contact centers to understand root causes of issues and find the optimal solutions quicker than ever. Agents can then achieve first call resolution, keep customers from churning and improve their overall experience.
Simplifying feedback collection
Measure customer satisfaction with NPS and CSI surveys and continually improve your service. Customers often find voicing their opinion more convenient, since it’s faster than writing or choosing answer options (and having to read the questions).

Using voicebots for such polls is a great option. They will be able to call all customers automatically and ask the necessary questions within a short period of time. Voicebots make the process of collecting feedback as efficient as it can get. They can be integrated with the company's CRM system, make records, synthesize and recognize natural speech.
How does speech recognition work?
Speech Recognition is a technology that converts speech to text in real time. It may also be called Speech-to-Text or simply transcription systems. You’re familiar with such systems if you’ve ever used virtual assistants such as Siri or Alexa. The technology is also implemented in automated subtitling, smart homes, and in-car systems.
Speech recognition systems usually leverage three major components – lexicon, the acoustic model, and the language model – to decode the audio signal and provide the most appropriate transcription.
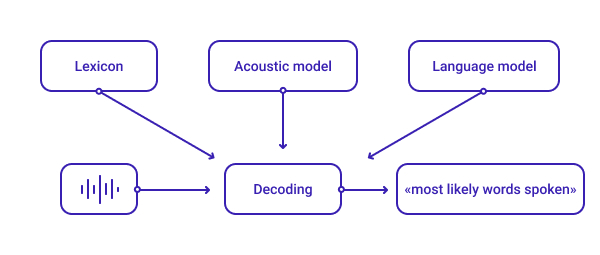
Lexicon
Some words can be pronounced in multiple ways. For instance, the word ‘read’ is pronounced differently depending on what tense is used, present or past. The lexicon contains all possible pronunciation options.
ASR systems use phonetic sets customized for each language. One of the most widespread sets is ARPABET that represents phonemes and allophones of General American English.
Acoustic Model
The next stage involves separating an audio signal into frames 25ms in length. Acoustic models analyze each frame and provide the probability of using different phonemes there. In other words, acoustic models aim to predict which sound is spoken in each frame.
Different people pronounce the same phrase in multiple ways. Factors like gender, background noise, and accent make it sound differently. Acoustic models use deep neural networks trained on hours of various audio recordings and relevant transcripts to determine the relationship between audio frames and phonemes.
Language Model
Language models recognize the context of spoken phrases to compose word sequences. Traditionally, language models of N-gram (groups of words) type predict the next word by known previous words.
Language models operate in a way similar to acoustic ones. They use deep neural networks trained on text data to estimate the probability of the next word.
All three components enable ASR systems to make predictions of what words and sentences were in the audio input. Based on these predictions, ASR systems choose the most likely prediction.
How does speech synthesis work?
Text-to-Speech (TTS) technology is the computer-generated simulation of human speech using deep learning methods. It’s commonly used by developers that build voice applications such as IVRs (Interactive Voice Response). This technology is also referred to as speech synthesis.
TTS saves time and money since it eliminates the need to manually record (and re-record) audio files. Instead of playing pre-recorded files, TTS automatically generates a human voice from raw text.
Voximplant provides an API to let customers easily integrate TTS functionality into their app or website. Customers use TTS to handle incoming and outbound calls, as well as manage voice notifications, and no hardware or complicated programming is required.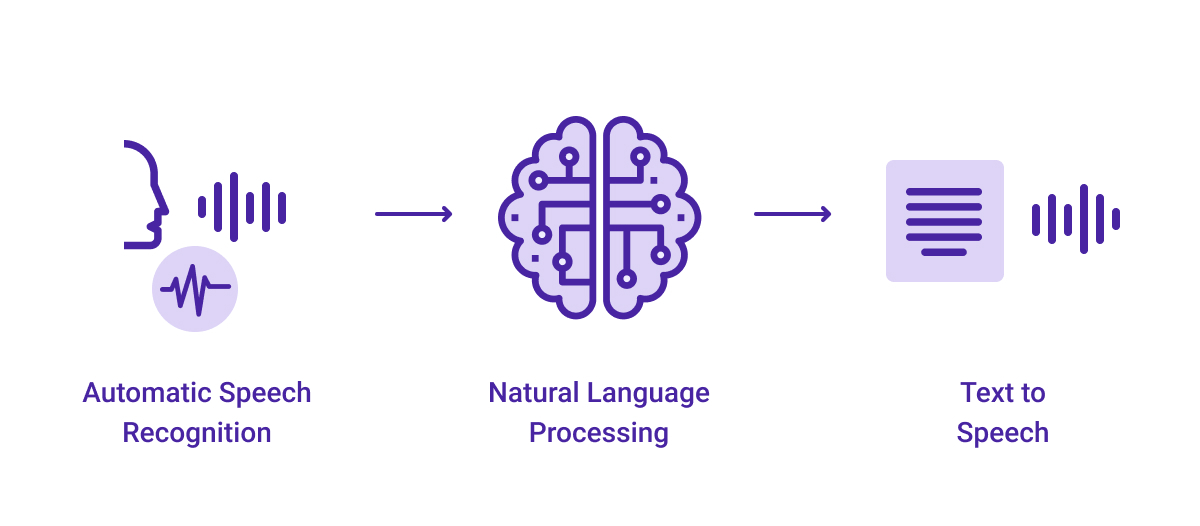 Let’s say a voice assistant recognized a text from a customer through your online service. To transform it into a voice, the system has to go through three stages: text to words, words to phonemes, and phonemes to speech.
Let’s say a voice assistant recognized a text from a customer through your online service. To transform it into a voice, the system has to go through three stages: text to words, words to phonemes, and phonemes to speech.
Text to words
First and foremost, an algorithm has to transform a text into a convenient format. The problem is that raw text is ambiguous. Components like numbers, abbreviations, and dates have to be decoded and broken down into words. Then, the algorithm separates the text into phrases to arrive at the most appropriate intonation. This includes punctuation and stable structures so that a robot can better understand a text and make fewer mistakes while reading.
Words to phonemes
Once the system has figured out the words to spell, a phonetic transcription has to be performed. In other words, the system needs to convert words into phonemes.
Each sentence can be pronounced in different ways depending on the meaning and emotions of the text. Moreover, even a single word can be read in multiple ways. For instance, there are lots of homographs, words that are spelled the same way but pronounced differently.
To understand how to pronounce a word and where to apply an accent, the system uses built-in dictionaries. If the necessary word is missing, the computer builds the transcription on its own, based on academic rules.
Phonemes to speech
Voximplant supports TTS powered by WaveNet to read prepared texts. The same technology is used by Google’s online services such as Google Assistant, Google Search, and Google Translate. WaveNet generates raw audio waveforms using a neural network, which has been trained on a large number of speech samples.All of the required information for speech generation is stored in the model parameters and the voice tone can be controlled through the model settings.
Businesses can find use for all of these advanced technologies and improve customer service dramatically.
Have any questions about how your business can benefit from speech technologies? We’ll be glad to answer them! Contact us today.
![]()





